![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
|
Contact |
|
R20/Consultancy |
|
+31 252-514080 |
|
|
|
|
Title: Flaws of the Classic Data Warehouse
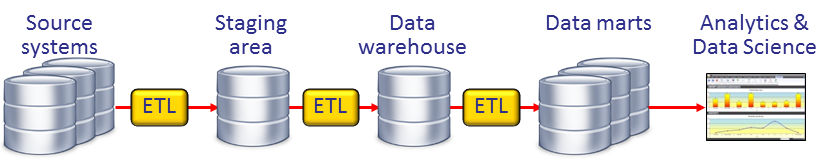
Abstract: The classic data warehouse architecture is based on a chain of data stores which are linked with ETL processes. These ETL processes copy data from one data store to another until its stored in one that is accessed by reporting tools. During the ETL processes the data is transformed, aggregated, and filtered.
This classic architecture has served us well the last twenty years. In fact, up to five years ago we had good reasons to use this architecture. The state of database, ETL, and reporting technology did not really allow us to develop something else. All the tools were aimed at supporting the classic data warehouse architecture. But the question right now is: twenty years later, is this still the right architecture? Is this the best possible architecture we can come up with, especially if we consider the new demands and requirements, and if we look at new technologies available in the market. Probably not. We are slowly reaching the end of an era. An era where the classic data warehouse architecture was king. Its time for change. This session discusses the flaws of the classic data warehouse architecture and proposes an alternative architecture, one that fits the needs and wishes of most organizations for (hopefully) the next twenty years.
Related Articles and Blogs:
 The Flaws of the Classic Data Warehouse Architecture, Part 1
The Flaws of the Classic Data Warehouse Architecture, Part 1
 The Flaws of the Classic Data Warehouse Architecture, Part 2 - The Introduction of the Data Delivery Platform
The Flaws of the Classic Data Warehouse Architecture, Part 2 - The Introduction of the Data Delivery Platform
 The Flaws of the Classic Data Warehouse Architecture, Part 3 - The Data Delivery Platform versus the Rest of the World
The Flaws of the Classic Data Warehouse Architecture, Part 3 - The Data Delivery Platform versus the Rest of the World
The Classic Data Warehouse Architecture: